Apache Airflow

Background: Data Warehouse and Data Lakes
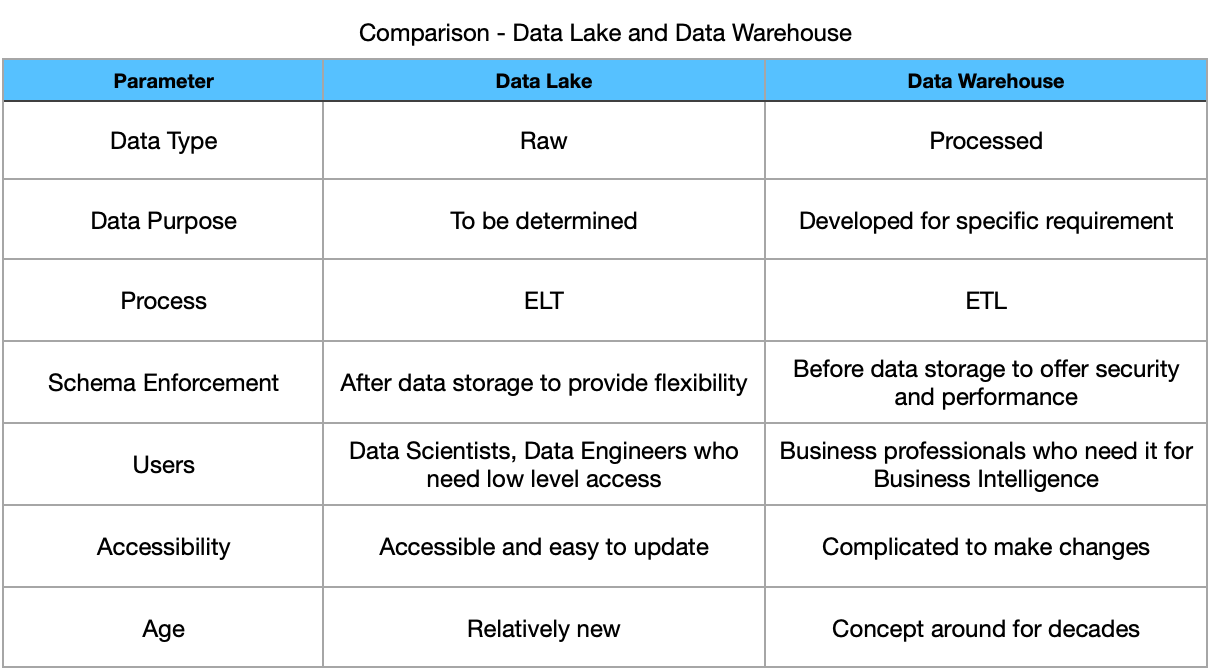
Data Warehouse
Data Warehouse is a type of data management system that is designed to enable and support business intelligence (BI) applications and analytics. The data in a data warehouse contains large amounts of historical data, is structured and the system is used to perform queries and analysis for a specific purpose. Data within the warehouse is derived from various disparate sources.
Data Lakes
Data lakes have multiple sources of structured and unstructured data that flow into one combined site of unstructured or raw data. Data Lakes are most suitable for applications like Machine Learning which require raw data.
Comparison: Data Warehouse and Data Lake
Extract - Transform - Load
- Extract - Replicate data from external sources
- Transform - Standardize the replicated data from varying formats used across varying data sources into common data model used by the application.
- Load - Pipe the newly formatted data into Date Warehouse or Data Lake
ETL (Extract - Transform - Load)
Transform data before loading it into a Data Warehouse
ELT (Extract - Load - Transform)
Load data into Data Lake. Tranform data later as per application requirements.
ETL - Advantages and Disadvantages
Advantages
- Greater Compliance: Companies subject to data privacy regulations, need to remove, mask, or encrypt specific data fields. ETL provides greater data security because it safeguards private data before putting in the data.
- Reduce Storage Costs: Because data is transformed before loading, only the relevant data is stored reducing storage costs.
Disadvantages
- ETL pipeline is very specific to a specific need. Every new process requires a new pipeline. This increases costs and decreases robustness of the system. Any change in upstream or downstream requires re-development.
ELT - Advantages and Disadvantages
Advantages
- Greater Flexibility and Simplicity: Does not require to develop complex pipelines upfront.
- Rapid Data Ingestion: Because transformation happens after loading, data can be ingested instantly.
- Transform Only the data you need
Disadvantages
- More Vulnerable to Risk: Data Privacy, Data Security Risk especially from the inside as ELT Admins have access to sensitive data.
- Less Established: ETL has been around for ages (Data Warehouses). Data Lakes and ELT is a relatively new concept.
Apache Airflow
Introduction
Apache Airflow is a batch oriented framework for building data pipelines. Using Airflow one can easily build scheduled data pipelines using flexible Python framework. It provides building blocks to integrate many different technologies. Airflow sits in the middle of data processes and coordinates work happening across different distributed systems. Airflow is not a data processing tool in itself.
DAG (Directed Acyclic Graph)
In Airflow a DAG is defined using Python and saved in DAG files. DAG files are Python scripts which describe structure. A programmatic approach to define a DAG provides a lot of flexibility. It can generate an entire DAG based on metadata. Also it can generate a task at runtime depending upon some conditions. It can execute any operation that can be represented as Python code. Airflow ecosystem includes Airflow extensions that can integrate with external databases, big data systems etc…
Scheduling Pipeline
Airflow has a facility to define a schedule interval for each DAG. Complicated intervals can be defined using cron-like expressions.
Airflow Components
Airflow Scheduler
It parses DAG, checks schedule interval and if applicable starts scheduling DAG tasks for execution by passing them to Airflow workers.
Airflow Workers
Pick up tasks scheduled for execution and execute them.
Airflow Web Server
Visualizes the DAG parsed by Airflow scheduler and provides interface to monitor DAG runs and their results.
Airflow Concepts
Airflow python script is just a configuration file specifying DAG’s structure as code. The actual tasks defined in the script will run in a separate context on different workers at different points in time. Python script cannot be used to cross-communicate between tasks. It is not the place where some data processing happens. The python script itself executes in seconds. The actual pipeline ofcourse can execute for much longer.


