Explaining Map Reduce

Hadoop Map Reduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data sets) in parallel, on large clusters of commodity hardware (thousands of nodes) in a reliable and fault tolerant manner.
A Map Reduce Job splits the input data-set into independent chunks which are processed by the map tasks in completely parallel manner. The framework sorts the output of map tasks which are then input to reduce tasks.
The Map and Reduce functions can be represented by following:
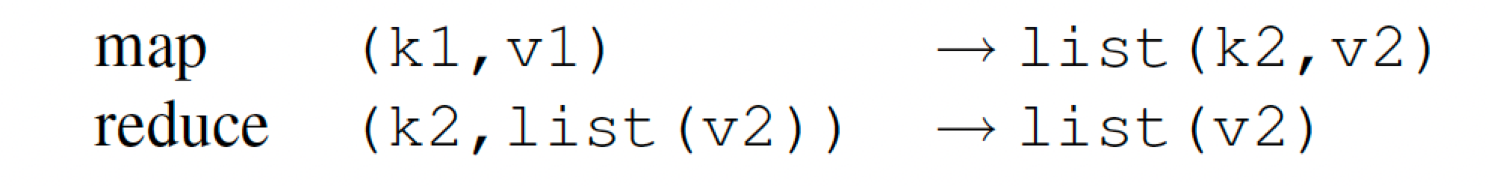
Explaining Map Reduce
This post attempts to explain map reduce in simple terms.
Problem Statement
It is easiest to understand Map Reduce by walking through an example. Let's consider a deck of 52 playing cards. Each deck has 4 suits: Hearts, Diamonds, Spades and Clubs. Each suit has 13 cards: 2 to 10 numeric cards, Jack, Queen, King and Ace.
The problem statement is to find sum of all numeric cards by suit. Therefore the expected answer is : Hearts (2+3+4+5+6+7+8+9+10) = 54. Similarly Diamonds = 54, Spades = 54 and Clubs = 54.
Intuition
The first step in decomposing a problem statement and evaluating whether Map Reduce paradigm can be applied or not, is to determine what (if any) steps can be parallelized. (Map Reduce is only suitable when a big chunk of data processing can be parallelized)
Considering the above example, since "each" playing card is independent and has no dependency on any "other" playing card, the summation activity can happen in parallel. (Note: it is not important whether the sum needs to be taken per suit or for the entire deck)
Lets imagine we have to solve this problem "manually" and we have 3 people who can do the task. How will we go about it ?
- The first step is to randomly divide 52 playing cards into 3 piles. (As there are 3 people. This is the split part in Map Reduce.
- Each person will independently calculate sum of all the cards in his/her pile per suit. This is the Map function in Map Reduce and multiple copies of the same function will be executed in parallel.
- Once all 3 people are finished, there will be a co-ordination activity where sums per suit of all 3 people are combined together to get ultimate answer. This is the Reduce function in Map Reduce.
Map Function
Definition

Input
For our specific problem statement, in whatever form the input might be, if we transform the input into a csv file with one record per line in the format: <suit>,<card_value> then we can use the csv file as an input to the map function. In this case the key: k1 will be one of 4 options: Spades or Diamonds or Hearts or Clubs and the value: v1 will be the actual card value. For example we can split the 52 playing cards and one of the splits can look like this:
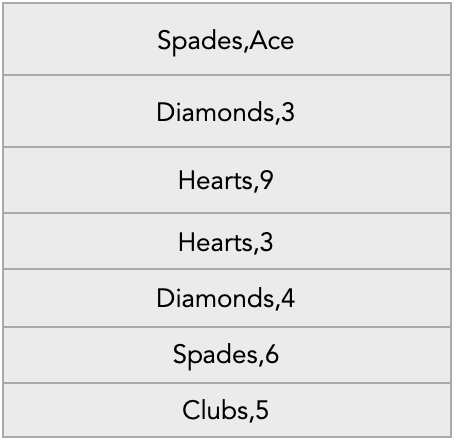
Processing
In this example, the work, the map function will do, is do a summation of the numeric cards per suit that it receives. It will acheive this by first discarding inputs cards with value Jack, Queen, King or Ace and then adding values of remaining numeric cards. For example if the map function received the input represented above, then after summation of numeric cards per suit, it will store the following as an intermediate state:
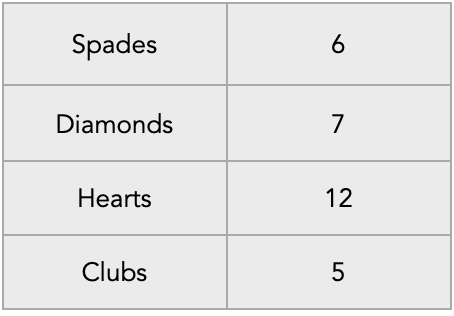
Output
As per definition the output of map function is list(k2,v2). Therefore in the example, it will be a list of all suits with intermediate summation of the cards it has received.
Reduce Function
Defintion
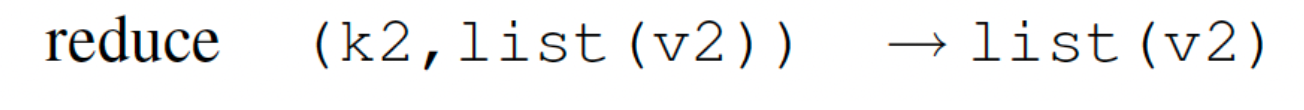
Input
The input to Reduce function is the output of all Map function executions combined together by key: k2. Therefore value: v2 will be a list whose size will be equal to number of map tasks.
Processing
The goal of our program is to do summation per suit. The "per suit" aspect is already handled by key: k2. Therefore all the reduce function has to do is go through the list and perform summation.
Output
The reduce function will output the summation value.
Summary
Map Reduce paradigm takes advantage of clusters to machines to perform analysis of large datasets. The steps of analysis which can be executed in parallel are done so using the Map function. Subsequently the Reduce function combines results of multiple executions of the Map function to provide intended output.


