Hadoop Distributed File System (HDFS)

What is HDFS ?
HDFS is a distributed file system designed to run on commodity hardware. HDFS is highly fault tolerant and provides high throughput access to "application data". It is suitable for applications which have large datasets.
Distributed File Systems are file systems that manage storage across a network of computers. It is more difficult for distributed file systems to provide fault tolerance and reliability (as compared to disk based file systems) because of two factors: 1) additional level of complexity introduced by the network and 2) probability of failure increases because more than 1 computer is involved.
Typically distributed file systems provide fault tolerance and reliability by using customized hardware for computers (RAID) as well as customized hardware for network appliances. (routers, switches, power systems etc...) The customized hardware (and software) increases the costs.
Uniqueness of HDFS is that it runs on commodity (and therefore cheap) hardware. Although HDFS runs on commodity hardware which are prone to failures, it is highly fault tolerant and provides high reliability. HDFS acheives reliability and fault tolerance using software. HDFS has taken some nifty software design decisions which facililate that.
Features of HDFS
#1 Hardware failure is the norm rather than the exception. Detection of faults and quick and automatic recovery is the core architectural goal.
#2 Provide access to large datasets. HDFS is designed to provide access to large datasets. To facilitate that HDFS is designed to provide batch access to datasets (rather than interactive use). Emphasis is on high throughput rather than low latency. (How much data can be sent rather than how soon can it be sent)
#3 Simple coherency model. HDFS is suitable for applications that need "write once read many times". In HDFS once a file is written, it can only be appended or truncated. (Files cannot be updated at arbitrary locations) These constraints simply data coherancy issues and enables high throughput data access.
#4 Moving computation is cheaper than moving data. Hadoop, Map Reduce and HDFS strive to ensure that execution is near the data it operates on. Since Hadoop is written is Java, it is possible for the application to be portable across heterogeneous hardware and software (Operating Systems)
HDFS Components
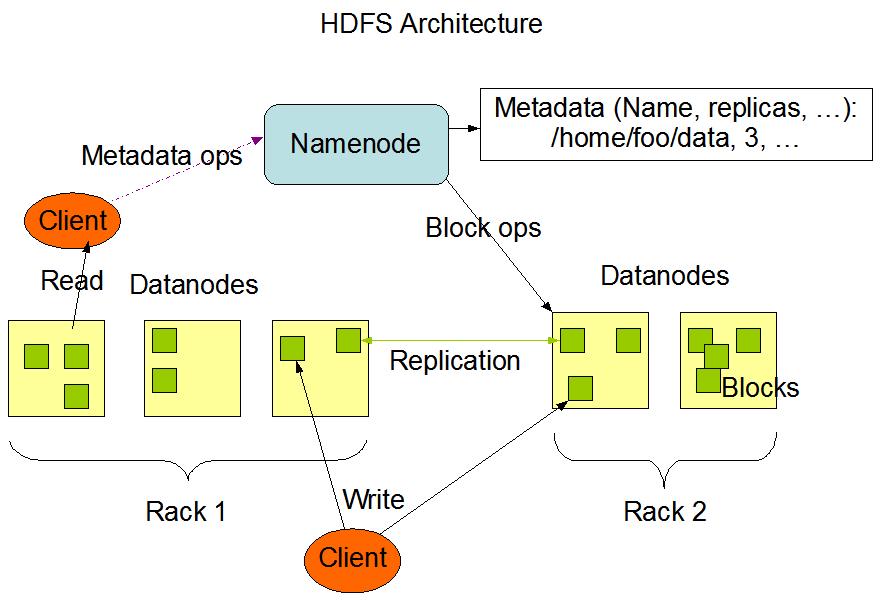
HDFS Blocks
Building "blocks" of HDFS are called blocks. (Represented by green boxes in above image). Before we understand HDFS blocks, lets discuss blocks from a typical File System perspective.
A physical disk has a block size, which is the minimum amount of data that it can read or write. (defined by hardware). A file system (software) deals with this by having it's own concept of a block which is an integral multiple of the block size of the physical disk. For example if disk block is 512 bytes, then file system block is of a few KB (multiple of 512 bytes). The concept of file system block is transparent for the users of the file system.
HDFS too has a concept of a block. The HDFS block is large in size (128 MB by default).
Files in HDFS are broken into block sized chunks and stored as independent units. Unlike in normal File System, in HDFS a file that is smaller than a single block does not occupy a full block’s worth of underlying storage. (1 MB file takes up 1 MB of space and not 128 MB of space)
Why are blocks so large in size in HDFS ?
The reason is to minimize cost of seeks. Blocks are distributed across different nodes in the cluster. The time to find a particular block in the cluster should be significantly less than time to transfer the actual data.
Name Nodes and Data Nodes
HDFS has a master / slave architecture.
A HDFS cluster consists of a single Name Node. Master that manages the file system namespace and regulates access to files by clients.
An HDFS cluster consists of many Data Nodes. Usually one per physical computer in the cluster. Data Node manages storage attached to the physical computer that they run on.
Name Node and Data Nodes are pieces of software designed to run on commodity hardware. Machines typically run a GNU Linux OS. The application software is written is Java. Therefore any machine that can run Java and has associated storage can run Name Node and Data Nodes.
Typical Deployment of HDFS
Name Node is on a dedicated machine. Each of the Data Nodes runs on a dedicated machine of the cluster. Existence of one Data Node simplifies the architecture. Name Node is arbitrator and repository of all meta data. User Data never flows through Name Node.
HDFS Working
HDFS exposes a file system namespace and allows user data to be stored in files. Internally a file is split into one or more blocks and these blocks are stored in Data Nodes. Name Node executes file system namespace operations like Opening a File, Closing a File, Creating a Directory etc...Name Node also determines mapping of blocks to Data Nodes.
Data Nodes are responsible for serving read and write requests from file system clients. Data Nodes are also responsible for performing block creation, deletion, replication on instructions from Name Node.
File System Namespace
HDFS supports traditional hierarchical file organization. A user and application can create directories and store files inside the directories. HDFS supports user quotas and permissions. HDFS does not support hard and soft links.
Name Node maintains File System hierarchy. Any change to file system hierarchy or its properties is recorded by Name Node. Application can specify number of replicas of a file that should be maintained by HDFS. Replication factor information is stored by Name Node.


