HDFS Architecture

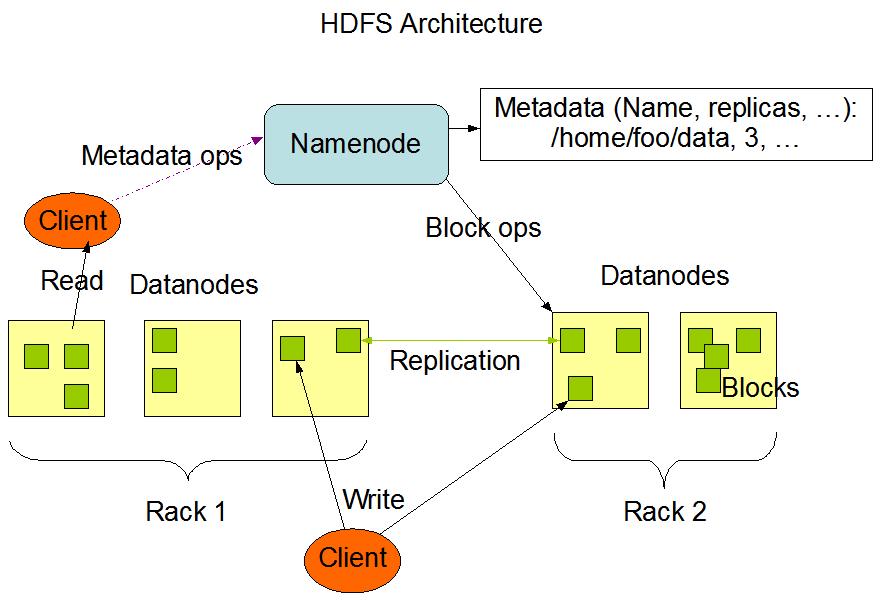
HDFS Architecture Diagram
Data Replication
How does HDFS manage to provide data reliability and high fault tolerance when it uses commodity (and therefore cheap and prone to failure) hardware ?
HDFS does it using a very simple idea.
- Break a large file into series of chunks or blocks (each block being 128 MB in size by default)
- Store each block on a different machine (Data Node) on the cluster.
- Replicate each block multiple times (3 by default) for fault tolerance
Block size and replication factor can be configured at an individual file level. Name Node makes all the decisions regarding replication of blocks. Name Node periodically receives a heartbeat and a block report from each Data Node. (Receipt of a heartbeat implies that Data Node is functioning properly. Block Report contains a list of all blocks in the Data Node).
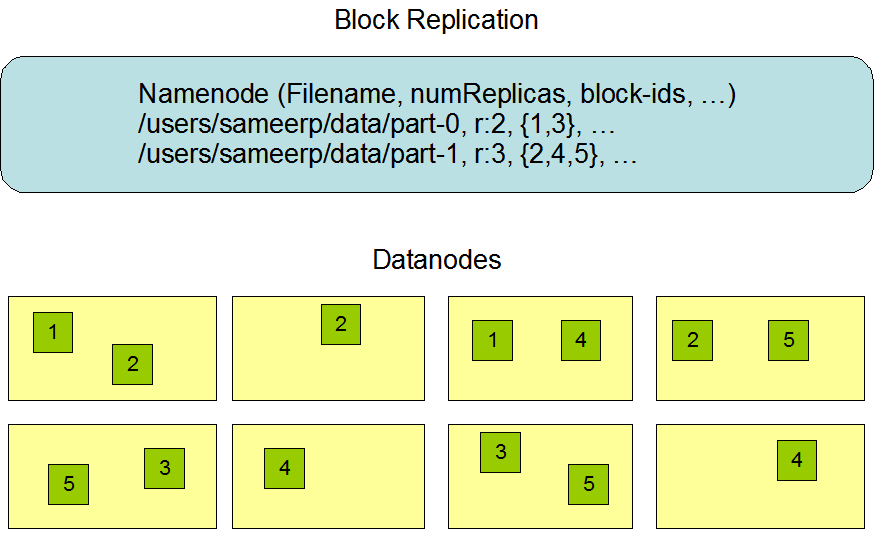
Important considerations in placement of replicas
The placement of replicas is critical to HDFS reliability and performance. Optimizing replica placement distinguishes HDFS from most other distributed file systems. HDFS has a concept of rack-aware replication policy to improve data reliability, data availability and optimum network bandwidth utilization.
Simple Policy
- Identify "rack id" of each Data Node (configuration)
- Put each replica on a different rack
This allows data recovery when entire rack fails (mainly because of network issues rather than failure of hardware). Allows use of bandwidth from multiple racks when reading data. Evenly distributes data so balances load in case of component failure.
The negative aspect of this simple policy is that cost of writes is very high. (Need to transfer same block to multiple racks).
Most Common Policy (For replication factor of 3)
- If writer is on Data Node then put the first copy on the same Data Node. If writer is not on Data Node then on some random Data Node.
- Send second copy to a Data Node on a different rack
- Send third copy to a different Data Node on the same rack (as that of first copy)
HDFS Safe Mode
When Name Node starts up, it goes into a special state called safe mode. Replication of data blocks does not occur when name node is in safe mode. In safe mode, Name Node receives heartbeat and block report from all Data Nodes. Block report contains list of data blocks hosted by that Data Node. A block is considered safely replicated when the block report from Data Node matches the data already present with Name Node.
After Name Node confirms that a certain percentage of such data blocks (percentage is configurable) are safely replicated, Name Node exits safe mode after waiting a further 30 seconds.
Even after exiting safe mode, if Name Node has identified certain data blocks that are not sufficiently replicated, it will initiate the process of replication of those blocks.
Name Node: Persistence of File System Meta Data
In HDFS, Name Node is the bottleneck as well as single point of failure. It is the bottleneck because all file systems operations are performed by Name Node. It is single point of failure because Name Node is the only node which has "full picture" of the files and directories created in HDFS.
Therefore it is important to make Name Node resilient. Architecturally it is achieved by storing File System Meta Data in two files (FSImage and EditLog) in the local file system of the machine where Name Node is deployed.
FSImage
FSImage is the file (stored in local file system of the machine where Name Node is deployed) in which entire file system (HDFS) namespace is stored.
Namespace means a list of all the directories and files (absolute paths) that are created in HDFS. It also includes additional information associated with the directories and files (who is the owner of the file / directory, what are the user | group | other permissions for those files and directories etc...)
The FSImage file also stores information about the mapping of files to blocks and mapping of blocks to Data Nodes.
Name Node also stores the copy of FSImage file in memory (RAM). It is done so that the response from Name Node is as fast as possible. Over the lifespan of HDFS, the FSImage file can get large in size. (Depends on how many files and directories are created and how big (in terms of number of nodes) the HDFS cluster is). Therefore while provisioning a cluster node for Name Node, care should be taken to provision sufficient RAM (8 GB, 16 GB etc...)
EditLog
Name Node also uses a transaction log (EditLog) to persistently record each and every change to the file system. The EditLog is appended every time a change in made to the file system.
It is important to note that the changes recorded in EditLog are reflected in FSImage stored in memory, but not to FSImage file stored on the local machine. This design decision is made considering performance. It is expensive to update a largish file on the hard disk for every change in meta data. (Updating FSImage in memory and appending to EditLog is relatively not expensive operation).
Therefore during normal operation the FSImage file stored on the disk becomes outdated. To handle this, Name Node has a concept of a checkpoint.
Name Node: Checkpoint
- When Name Node starts up (or after a configurable threshold) a checkpoint is triggered
- At checkpoint, the Name Node clears the FSImage copy from memory and reads the FSImage file from the disk into memory
- Applies (if any) EditLog transactions to FSImage file loaded in memory
- Flushes out new FSImage to disk
- Subsequently, Name Node clears out the records in EditLog as they are already reflected in FSImage stored on disk
- During the execution of checkpoint operation Name Node does not allow clients to make changes to meta data
Data Nodes: Persistence of blocks
Data Nodes stores HDFS blocks into local file system of the machine where Data Node is running. It is important to note that Data Node is not aware of HDFS file system, file system hierarchy, permissions etc...
Each block is stored as a separate file in the local file system. Data Node does not create all the files in the same directory. It applies heuristic to determine optimum number of files per directory and then creates sub-directories.
Block Report
During startup and then during heartbeat, Data Node scans though the local file system, generates a list of HDFS data blocks that correspond to each local file, calculates the checksum for each data block and send this report to Name Node.
Communication Protocol
All communication protocols in HDFS are layered over TCP/IP.
- Client establishes connection with Name Node using a known (configurable) tcp port. It talks ClientProtocol with Name Node
- Data Node talks to Name Node using the DataNodeProtocol
- A RPC wrapper exists for both ClientProtocol and DataNodeProtocol
HDFS Federation
NameNode keeps reference to every file and block in memory using FSImage. Therefore memory becomes limiting factor in case of a large cluster with many number of files. HDFS Federation allows a cluster to scale by adding multiple Name Nodes each of which manage a portion of the file system.
- /user - One Name Node
- /share - Another Name Node
Name Node volumes are independent of each other. They do not communicate with one another. Also failure of one Name Node has no impact on other Name Node. To access Federated HDFS, clients use client side mount tables to map file paths to Name Nodes.
Secondary Name Node
From HDFS perspective, NameNode is the single point of failure. Therefore it is possible to run a Secondary Name Node. (Despite it’s name does not act as a Name Node). It’s role is to periodically merge FSImage with EditLog to prevent edit log from becoming too big. Secondary Name Node can be used incase of Primary Name Node failing (with some downtime)


